
KV Cache
KV Cache的存在本身是为了解决在Decoder模块中的Attention计算效率的问题:其核心思想是将Encoder模块计算得到的Key-Value对缓存起来,以便Decoder模块在计算Attention的时候直接使用缓存的Key-Value对,而不需要再次计算。
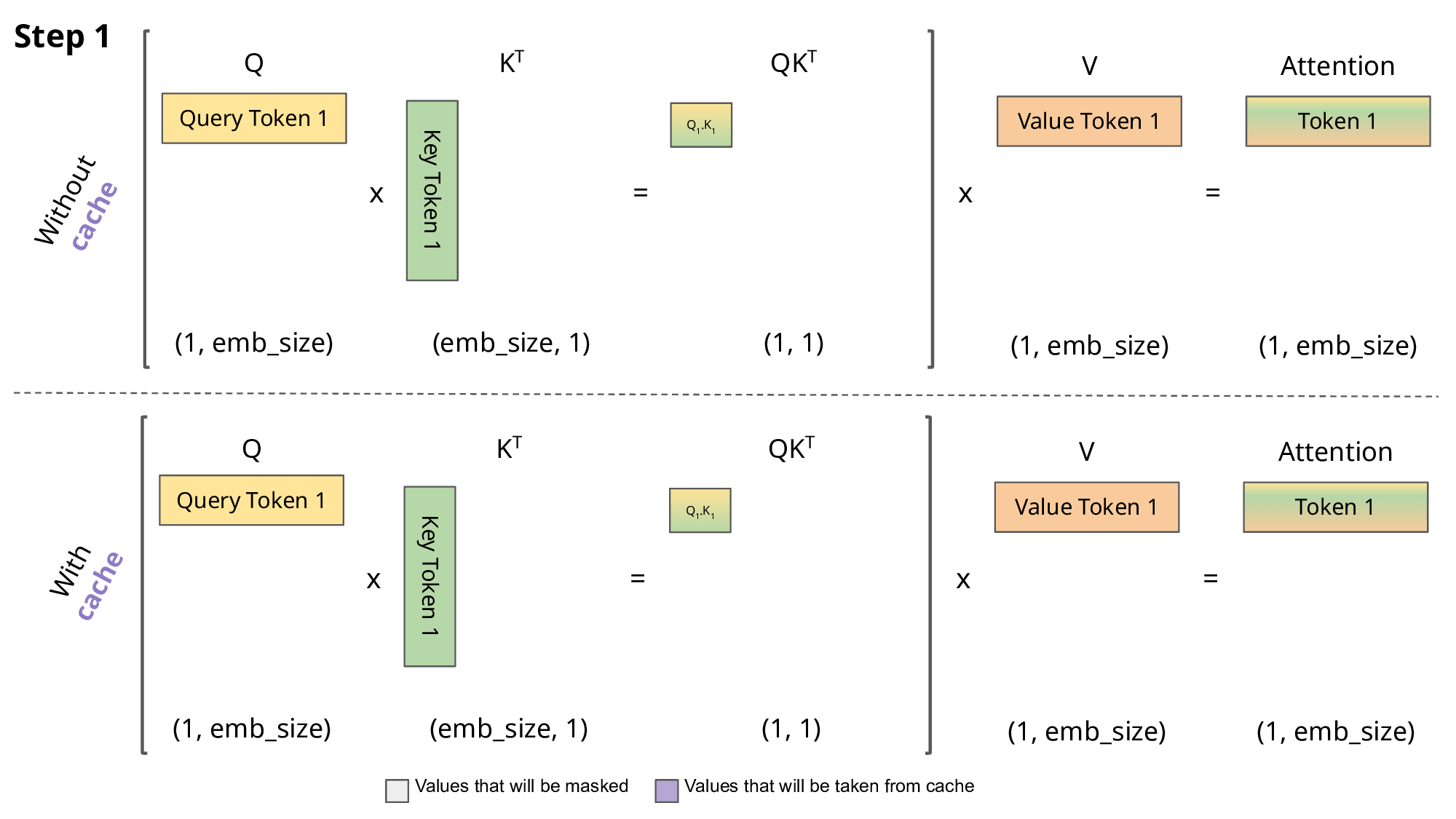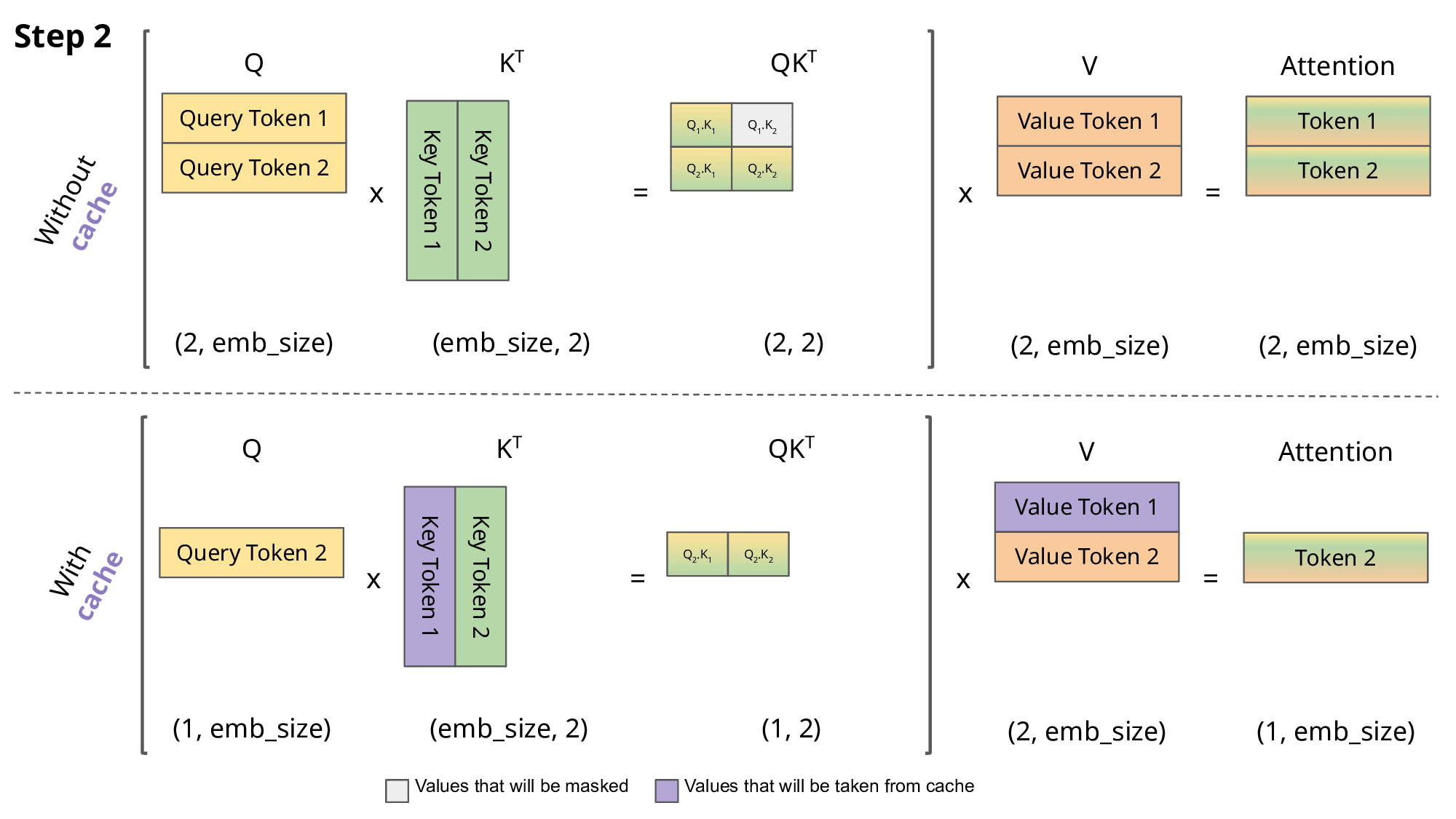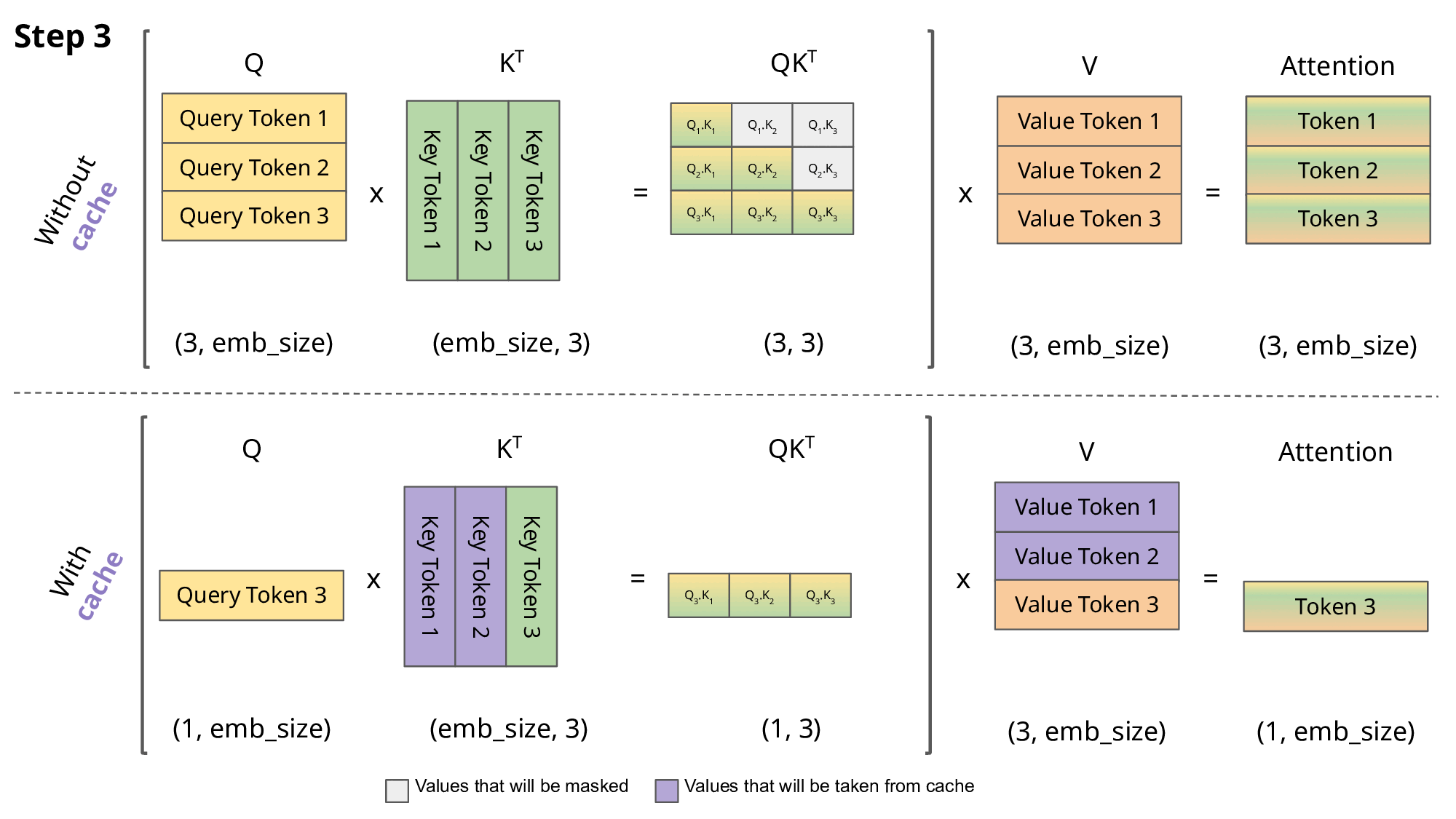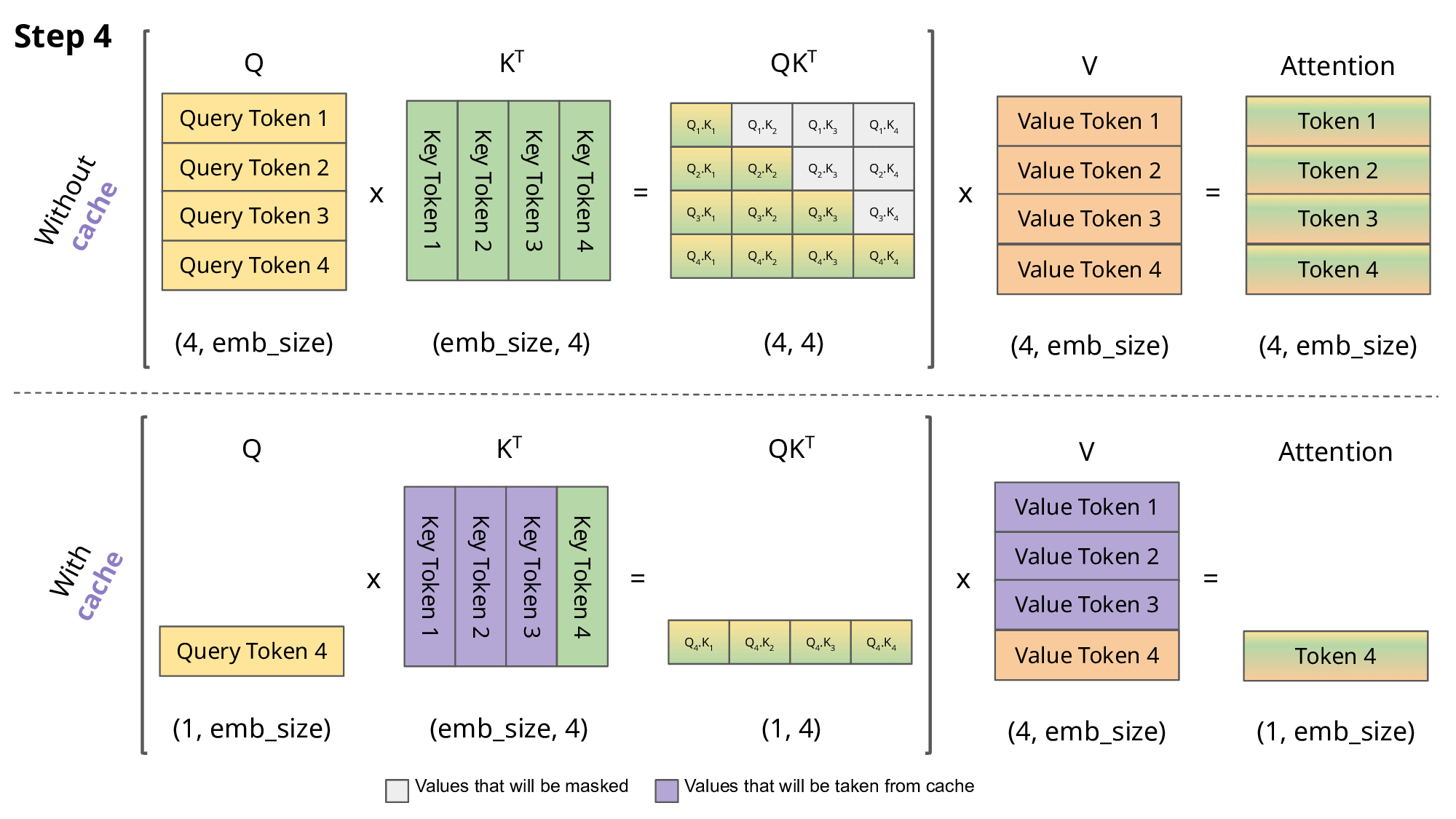
LLM针对Inference过程主要会分为两个阶段:
- 计算密集型的Prefill阶段:针对用户的输入计算出对应的KV Cache
- 评价指标主要是TTFT(Time To First Token)
- 显存密集型的Decode阶段:根据显存中的KV Cache来生成对应的Token
- 评价指标主要是TPOT(Time Per Output Token)
但是存储KV Cache本身也会带来很多问题以及有很多优化的空间:
- KV Cache在词典很大的时候会占用很大的显存
- 不同的Inference过程如果有类似的内容是否可以复用KV Cache里面的内容
- Prefill和Decode阶段分离部署在不同的设备上
Prompt Cache
Prompt Cache便是针对第二个问题提出的一个方案,其针对的场景就是有大量的提示词可以被复用,便可以在KV Cache的基础之上,将注意力状态复用从单个提示请求扩展到了多个提示请求。想要实现Prompt Cache有两个问题需要解决:
- 注意力状态是位置依赖的,系统最终的目标要是:即使文本段在不同提示中出现在不同位置,注意力状态也可以被复用
- 系统必须要能有效的识别出其注意力状态可能已被缓存的文本段,以便能够复用
Implementation
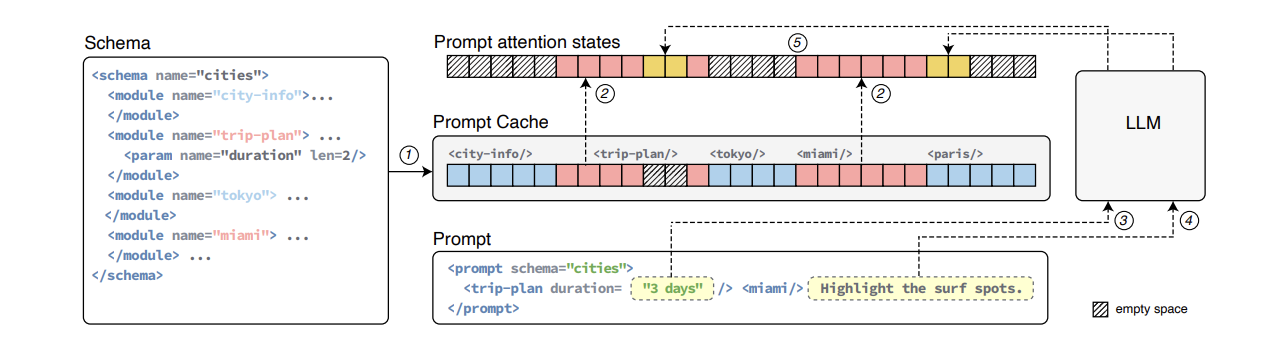
针对上述的两个问题,本文提出了对应的两种策略:
- 使用PML语言(Prompt Markup Language)来显示标记一个提示的结构
- 基于实验研究发现,LLM可以在具有不连续位置ID的注意力状态下运行(只要保留标记的相对位置,输出质量不会受到影响)
PML的使用方式如下:
- 用户先要从Schema(也使用PML完成)中推导出一个Prompt(即PML的一种实例)
- 可以使用参数在Prompt模块的开头或结尾创建一个“缓冲区”
通过这些方法,Prompt Cache主要对Memory存储机制和Attention计算机制进行了优化:
- 使用PyTorch的Memory Allocator将内容存储在CPU DRAM和GPU HBM中
- Attention模块需要支持不连续的位置ID(在通常来说,模型是通过Position ID的位置从KV Cache中获取到对应的KV信息的)
- 解决方式主要是通过创建一个Lookup Table来实现的
KV Link
KV Link主要针对的场景如下:在RAG的过程当中,我们通常需要针对Document进行Encode的操作,但是当不同的查询共享相同的文档时,模型会冗余地重新编码这些相同的文本,尽管它们的内容并未发生变化。KV Link的目标是通过共享文档的编码来减少这种冗余。这也是对KV Cache中问题二的一个解决方法。
KVLink通过预先独立计算每个文档或文本片段的关键值(KV)状态,然后在推理过程中重复使用这些预先计算的状态,从而实现去除冗余计算的作用。但是直接的将文本的KV状态进行拼接会造成很严重的性能损失,性能下降的原因在于,Transformer的注意力机制通常是建立在前后文的环境中的,Context-Free的编码模式会破坏这样的前后文关系,带来非常显著的性能损失。
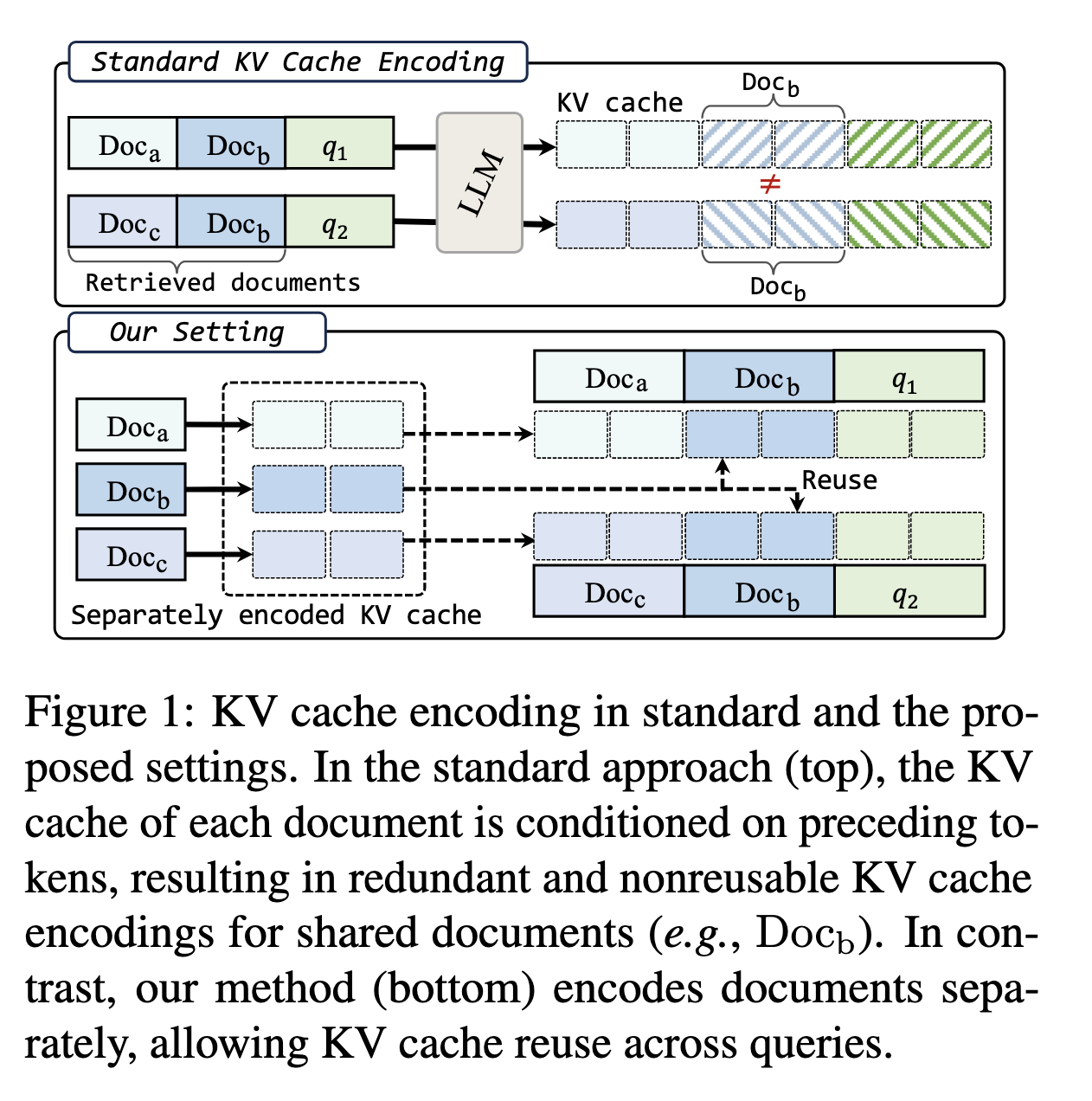
因此,本文提出了三种主要的策略:
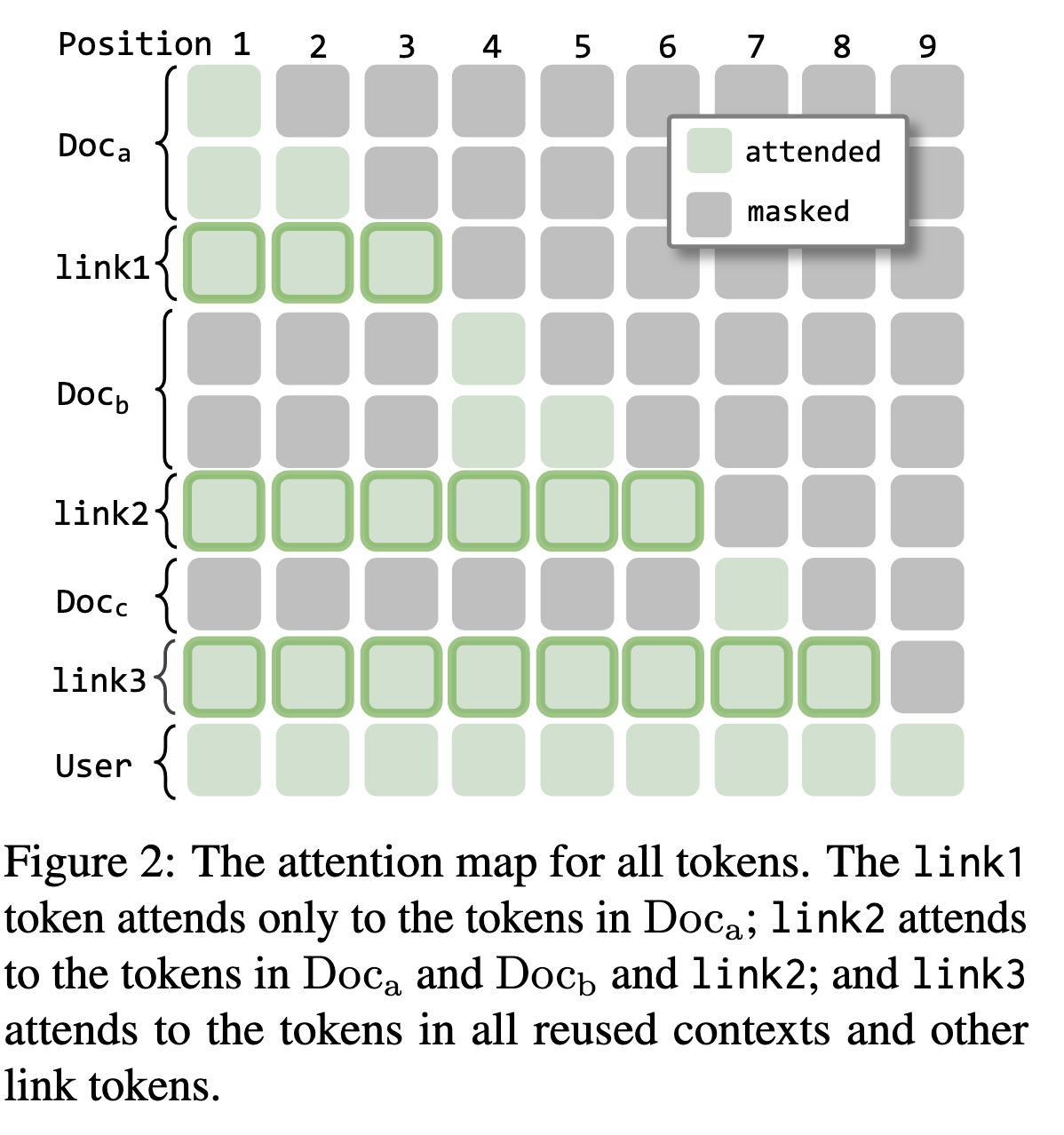
- KV cache positional re-encoding
- RoPE是现在主流的LLM模型使用的Positional Encoding策略,在存储KV Cache的过程中首先要Decouple RoPE的过程,存储不带有Position Embedding信息的KV Cache
- Trainable cross-segment special tokens
- 同时KV Link使用了Link Token在不同的Document中间作为链接,这样每一个Link Token的引入都可以和前面使用的Doc进行Attend的过程
- Fine-tuning with a diverse data mixture
- 目前的LLM并没有针对这种场景的训练,所以本文使用了Mixed Dataset来增强模型的泛化能力
这篇文章的出发点很有意思,但是有一个比较大的问题就是,其模型带来性能提升最大的地方在于其使用了Mixed-Dataset来进行Finetune,而实际的Link Token似乎并没有对模型能力的提升有太大的帮助。
StreamingLLM/Attention Sink
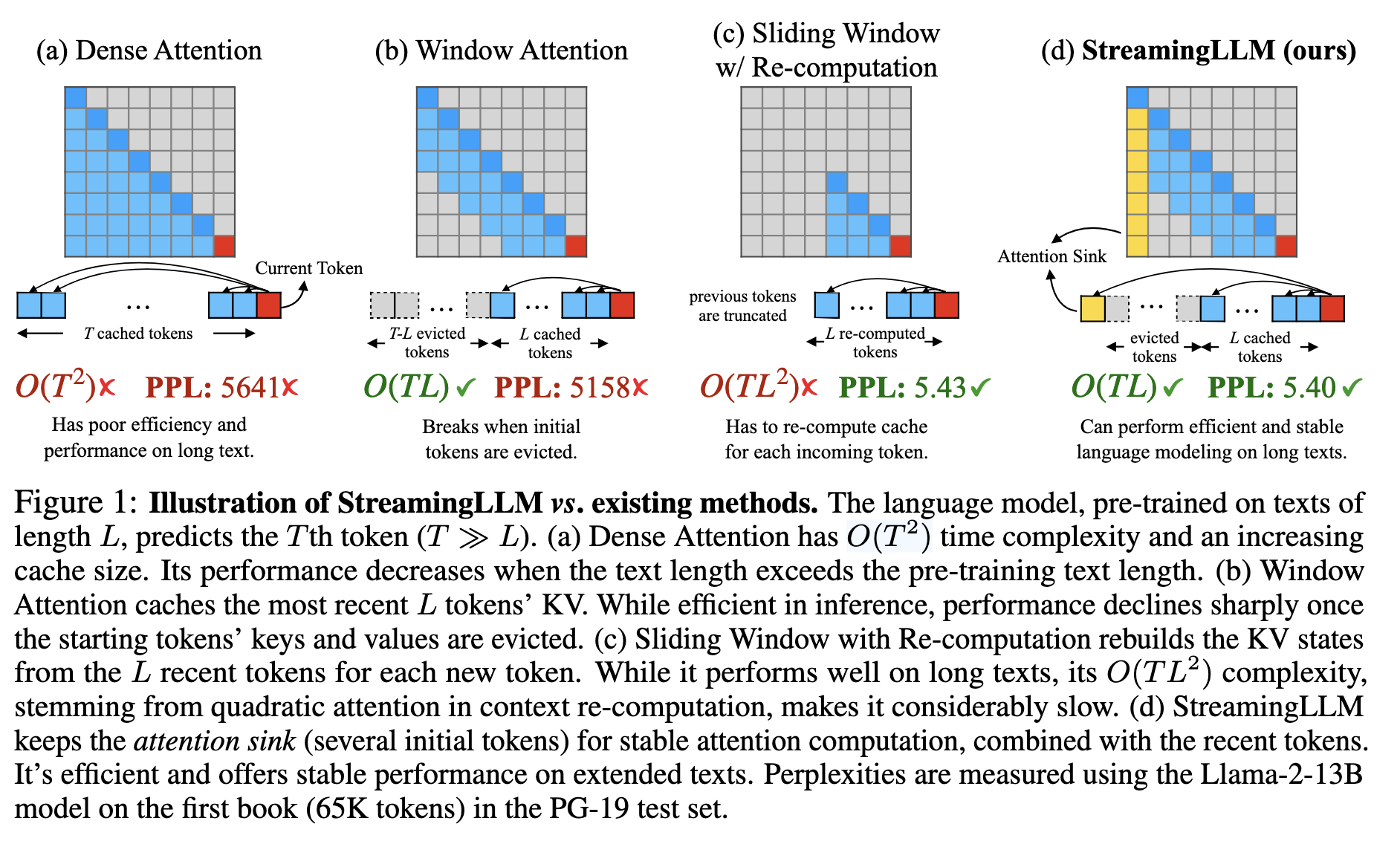
StreamLLM主要研究的是在KV Cache显存有限的情况下,如何提升Attention的计算性能,其主要解决的事KV Cache中的第一个问题。文章发现,在Attention计算的过程当中,Attention Score的计算相当依赖于第一个Token。在Window Attention计算的过程当中,前文内容往往会随着Attention计算而被遗忘,这种Attention Sink的现象可以帮助我们在减少显存使用的基础之上,同时还可以提升Transformer对于文本的理解能力。
CachedAttention
CachedAttention是一个偏系统性的工作,它针对的场景主要是在用户的多轮对话中对于KV Cache的复用问题,通过维护一个分层的KV缓存系统,利用经济高效的内存/存储介质来保存所有请求的KV缓存来缓解KV Cache对显存占用的压力:
- 分层预加载和异步保存,来将KV缓存访问与GPU计算重叠
- 使用调度器感知的获取和置换的方案,根据推理作业调度器的提示,有意识地将KV缓存放置在不同的层级中
- 解耦位置编码和有效截断KV缓存,使保存的KV缓存保持有效。
Mooncake
Mooncake的工作就是针对PD分离进行的一个偏系统性的工作