动态规划整理笔记
动态规划实在是学的让人头大,很多问题也分析的不是很清楚,感觉有必要要把学习到的知识做一个整理和归纳。学习的路径是先从课本上举的例子开始,然后会对作业的题目做一个简单回顾,后面是根据OI-Wiki上面提及的知识点的一些整理归纳。
写在前面:对于动态规划问题,我觉得最难受的地方不在于写代码。和所有问题不同,动态规划的代码量非常少,但是往往设计不好就会导致很高的时间复杂度和空间复杂度,对于动态规划状态的定义和对于动态规划的时间空间优化都是需要深入探讨的课题。不知道有多少时间来完成这个笔记,于是写到哪里就记录到哪里吧。
课本上的动态规划问题
在课堂中,使用的教材是Jon Kleinberg 和 Eva Tardos 的 Algorithm Design,课本中的例子都十分经典,由浅入深,详细讲到了各种有关动态规划的各个方面和需要关注到的一些优化的细节。
💡 Those who cannot remember the past are condemned to repeat it.
基础篇:
- Weighted Interval Scheduling
- 从贪心到动态规划:动态规划可以解决什么问题?
- 动态规划的两种策略:Top-down和Bottom-up
- Maximum Subarray Problem
- Kadane’s Algorithm:通过提前将所需数据存储起来降低时间复杂度
- Bentley’s Algorithm:二维推广
- Segmented Least Squares
- 时间复杂度降低思维应用
- Knapsack Problem
- 经典背包问题,复杂变体非常多样
- 完全背包问题、多重背包问题等等
- 空间压缩思维应用
- RNA Secondary Structure
- 条件限制下的动态规划问题
- 遍历顺序对于动态规划问题的重要性
进阶篇:
- Sequence Alignment
- Hirschberg’s Algorithm:分治思想和动态规划问题的结合,降低空间复杂度
- Longest Common Sequence
- Bellman-Ford-Moore Algorithm
- Distance-vector Protocols
- Negative Cycles
Bellman-Ford-Moore Algorithm
最简单的BFM算法可以用下面的表达式直接表述:
If
then:
uses at most edges. - If the path uses
edges and the first edge is , then
The pseudo code can be written as follows:

时间复杂度:
空间复杂度:
显然这是有很大的优化空间的
Improvements
Basic Time Improvement
时间复杂度是
Space Improvement
可以发现,上述的Recurrence Relation虽然涉及到
因此我们的Recurrence Relation可以写为:
法
Pull-based Algorithm
上面讲述的算法本质上是一种拉取信息的算法,也就是我们在每一次遍历的时候,都让每个节点从相邻的节点拉取一次
Push-based Algorithm
进行了Push-based优化后的算法有一个新的名字:SPFA(Shortest Path Faster Algorithm)也可以理解成是BFM算法进行队列优化后的结果。Push-based的优化基于一个假设,就是我们只希望遍历那些被更新过的节点的邻接节点(因为大概率这些邻接节点也会被更新),为了维持这种特性,我们需要一个队列来维护这个性质。也就是每次都把会被更新的节点添加到这个队列当中。



第二种方式是我们提及的用队列来优化的伪代码。
Question
- 我们希望找到最短路径,如何去寻找最短路径
- 我们希望判断其中的负环,如何去检测负环
- 在Push-based的方法中,我们算法复杂度虽然提升了,但是出现了信息差的问题(因为信息是Local的),比如下面这种情况:
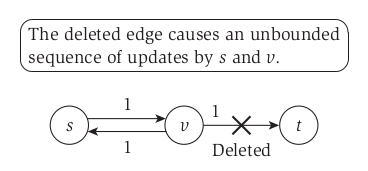
当我们的
Lab 8 和 Lab 9 中的动态规划问题
Lab 8A
一个背包问题的变种,多重背包问题,在后面会详细展开讲,此处跳过。
Lab 8B
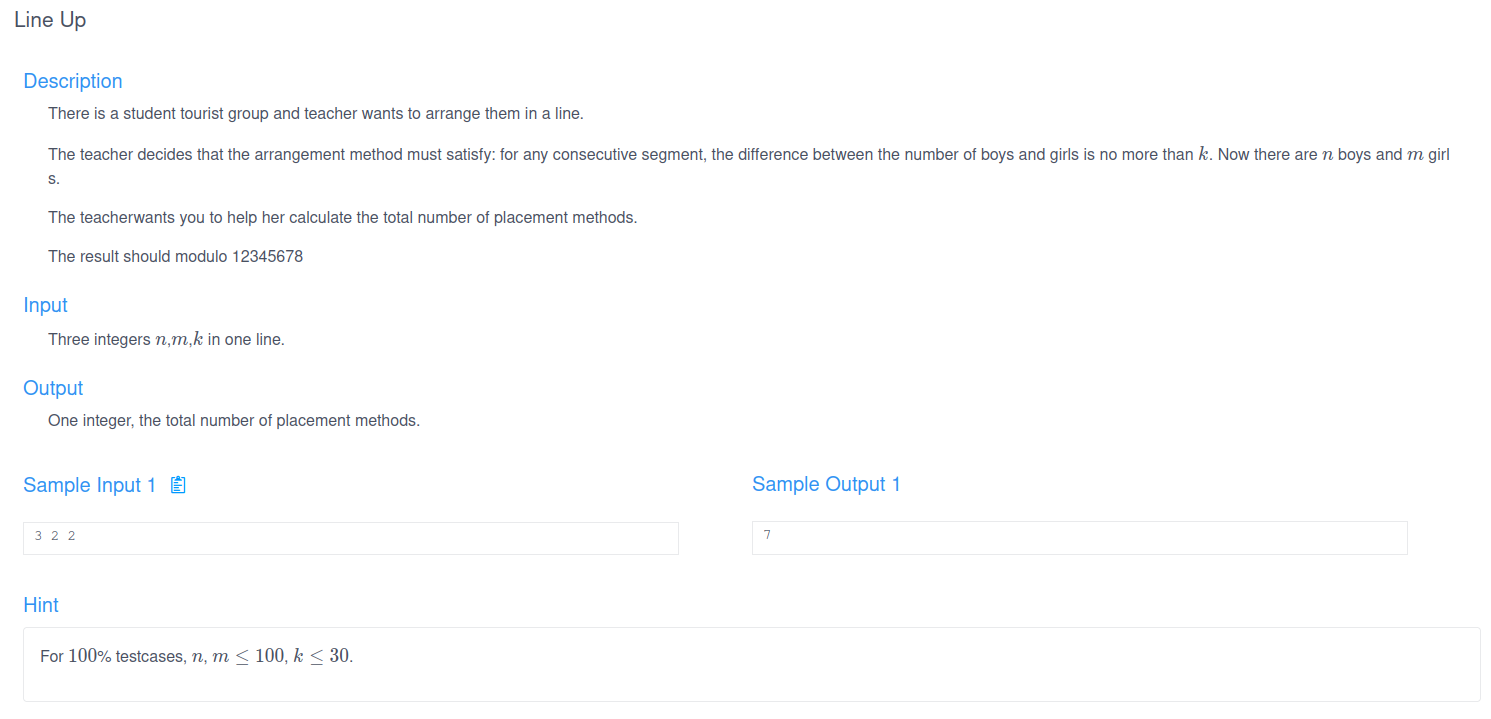
此题目是一个非常容易误判的题目,让人对此题的难度产生错误预估。将在这里阐述一下我一开始的天真想法,和在hyj同志指点之后的改正思路。
问题分析
题面其实非常简单,简单可以理解成一个长度为
天真的思路
我真傻,真的,如果提前看到了数据范围,难道还会想出这么Naive的解题思路吗? —追悔莫及的登
是的,从数据的大小判断,该题的时间复杂度应该在
我的状态转移方程是这么构建的:
在遍历过程中,我对
00001111111 // 假设此处k=5,显然每一步都是可以通过特判的,但是仍然不符合题目要求正确的思路
从一个直观的角度思考我这个做法,其实就是在做一个最短路径查找问题:即从
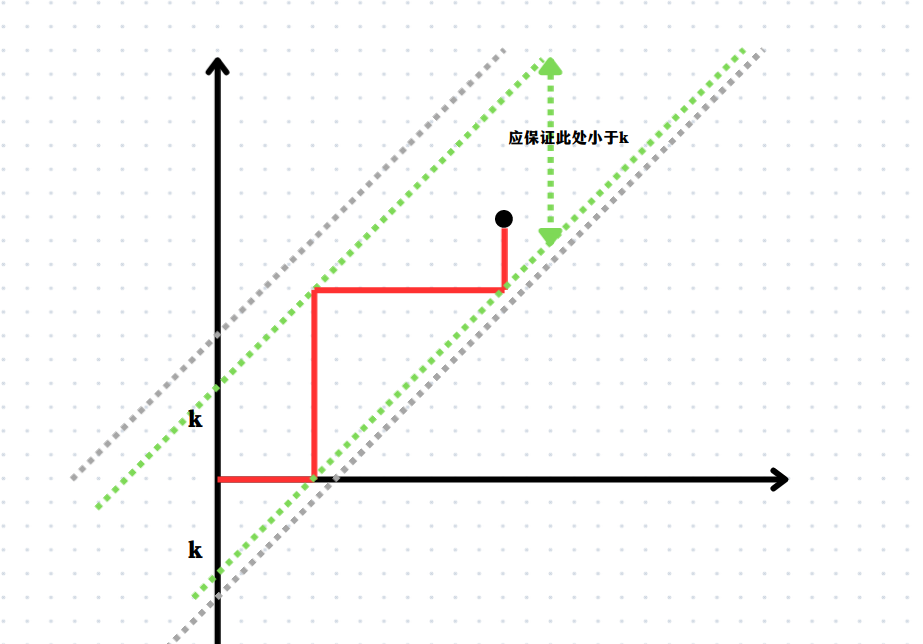
那我们现在可能就要考虑一个问题了,如何在原有的基础之上作出一些修改就能得到我们的结果呢?其实从我们上述的分析中已经可以得出了,我们还需要记录的状态就是这个最大值和最小值,要保证每一次递归的时候最大值和最小值之差不能超过要求。那么其实我们需要的就是一个四层的状态转移方程,需要注意的是,由于我们定义的是一个状态,状态转移方程从现在推未来会更加方便,而如果从过去推现在,我们无法提前预知
最后是遍历顺序,此处对于遍历顺序没有什么讲究,因为是加和而不是替换,原有的都会被保留下来,但是要注意初始化,不然可能加出来的答案有问题。
最后结果应该是
Lab 9A
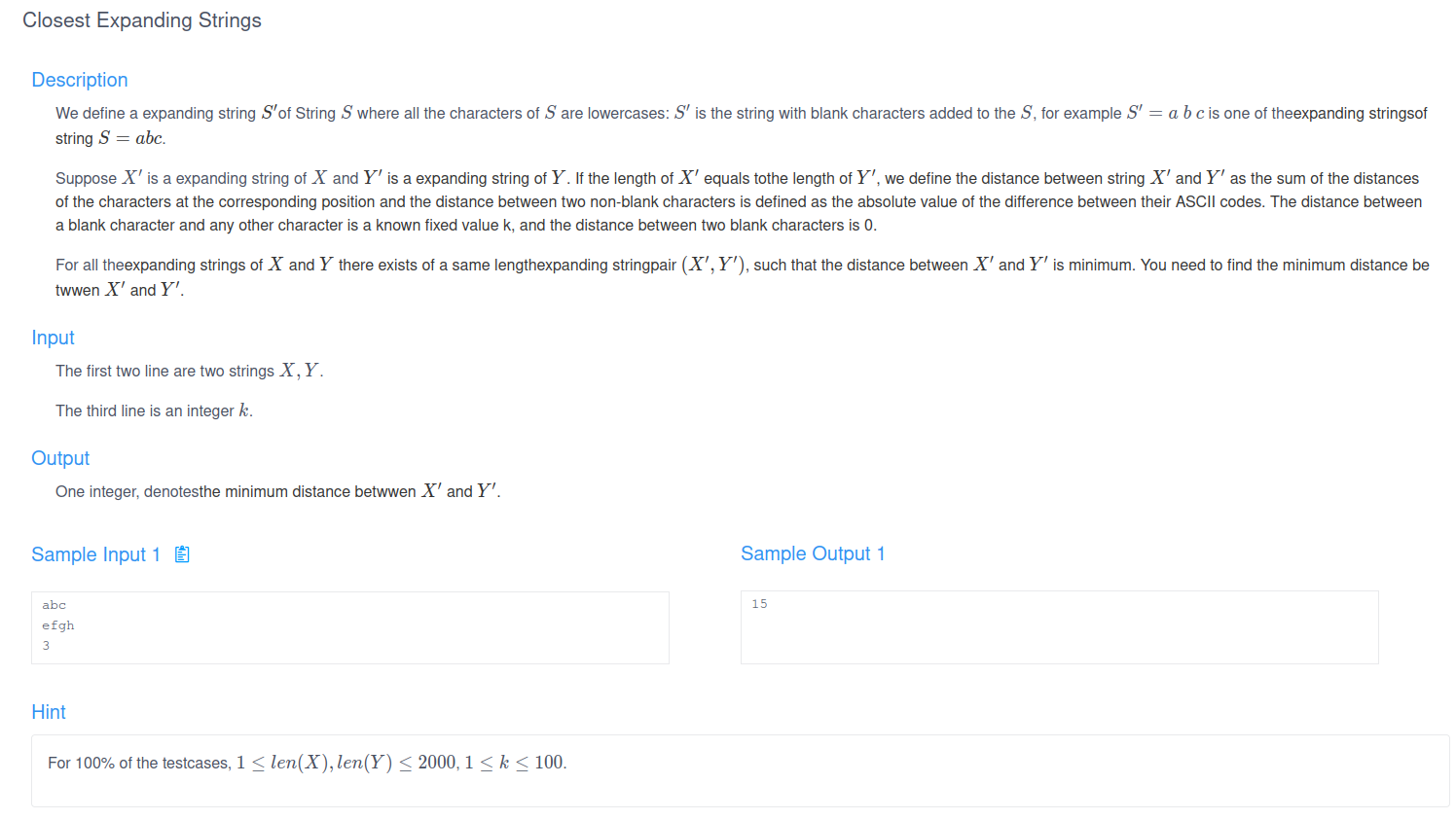
这个题目是一个Sequence Alignment问题,甚至不能算变体,因为状态转移方程完全一样,简单列一下:
Lab 9B
又是一道非常难顶的题目 T T,自己天真的思路虽然没有之前那么天真了,但是还是没有办法把所有情况考虑周全,而且算法虽然结果似乎正确,但是非常不高效(更好笑的是错误的思路竟然可以通过学校的OJ,可见数据其实不是很紧)
问题分析
这个问题就比Lab8的问题要稍微难分析一丢丢了,以至于我今早之前(4月23日)一直按着错误的思路在反复摸索,然后今天一读题发现不太对劲。
题目提出的是一种压缩算法,用两个字符来对字符串进行压缩:
- “B”代表了压缩的开始,并不代表任何的字符
- “R”代表了将从字符“B”后到“R”前的字符串重复一遍
有几个要注意的地方(也是为什么我的代码会有问题的地方):
- 如果开始压缩的地方在开头,那么“B”可以省略(这是个很好的条件,也是个很好的提示,但是我完全忽略掉了)
- “R”只跟最近的“B”字符进行匹配(那么就提醒我们在想进行多重压缩时,有些压缩是进行不了的,因为没有办法还原,这就是我没考虑到的问题)
如果要举一些例子的话比如:
kabaabaabaabaxabaabaabaaba => kBabaRRxBabaRR
kabaabaabaabaabaabaabaabax => kBabaRRRx // 可以发现这种压缩其实是一种指数级别的压缩,如果重复片段很多的话会有很高效的压缩效果,以及这种指数级别的压缩也方便了我们的判断
kacabaabaabaabaacabaabaabaaba => kBacBabaRRR x kacBabaRRacBabaRR v // 示范,此处最后一个R本来应该和第一个B匹配,但是由于歧义问题最后其实是不能压缩的天真的思路
其实一开始拿到这个题目是完全无法下手的,感觉和平时的
我的想法很简单,就是与普通的区间
但是和普通的区间
- 从
位置开始枚举,不断把 的长度翻倍来看是否能够符合要求,不符合要求就标记无法压缩
bool flag = true;
int r_cnt = 0;
int t = i + len;
for(; t + len <= j + 1;){
if(s.substr(t, len) != s.substr(i, len)){
flag = false;
break;
}
r_cnt++;
t += len;
len <<= 1;
}- 然后判断是什么情况,该段最小压缩(包括
)加起来压缩后需要几个字符串,对边界条件进行一个特判
if(i == 0){
if(t == j + 1){
dp[i][j] = min(dp[i][j], dp[i][k] + r_cnt);
}else{
dp[i][j] = min(dp[i][j], dp[i][k] + r_cnt + dp[t][j]);
}
}else{
if(t == j + 1){
dp[i][j] = min(dp[i][j], 1 + dp[i][k] + r_cnt);
}else{
dp[i][j] = min(dp[i][j], 1 + dp[i][k] + r_cnt + dp[t][j]);
}
}这种做法可以通过OJ上的题目,但是没有办法通过洛谷的题目(只有kacabaabaabaabaacabaabaabaaba 这个字符串,我的算法就会很好地掉入陷阱当中。(谁叫我是蠢蛋呢?)于是在题解的帮助下,我理解了这道题目的正确思路
正确的思路
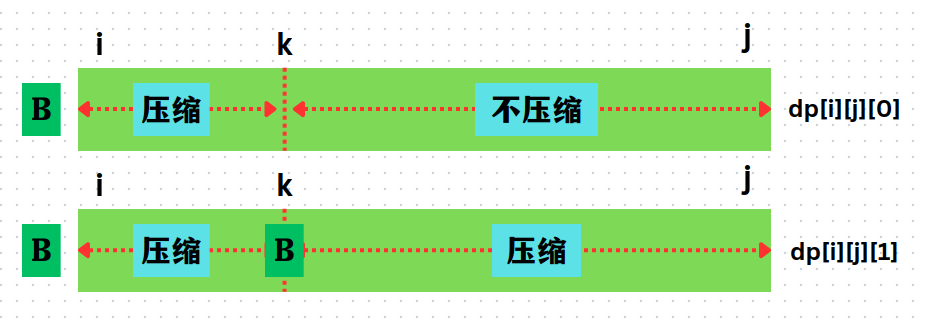
对于这道题目其实利用区间

题目条件也给了我们提示,在
- 这个区间里面没有其他的
出现了 - 这个区间里面还有其他的
因此我们在原有的基础之上还需要拓展一个状态:
现在有一个问题就是要对所有的check 是只需要检查前半部分和后半部分是否相同,这样就可以看一个子字符串是否具有压缩的潜力。
bool check(int l, int r){
int len = r - l + 1;
if(len % 2 == 1) return false;
len >>= 1;
if(s.substr(l , len) != s.substr(l + len, len)){
return false;
}
return true;
}
if(check(i, j)){
int mid = (i + j) >> 1;
dp[i][j][0] = min(dp[i][mid][0] + 1, dp[i][j][0]); //初步压缩
}