End-to-End Object Detection with Transformers
DeTR stands for DEtection TRansformer is a set-based global loss that forces unique predictions via bipartite matching and a transformer encoder-decoder architecture.
Background
The goal of object detection is to:
- predict a set of bounding boxes
- categorize labels for each object of interest
The methods used are:
- Proposals: Generate sets of possible regions, then by using techniques like NMS to locate on one most probable region.
- Anchors: Used as reference point to predict the positional adjustments for each anchor relative to the true location.
- Window centers: Non-anchor based methods.
The methods used before are strongly restricted by the postprocessing steps. This essay proposed an end-to-end direct prediction method.
Structure
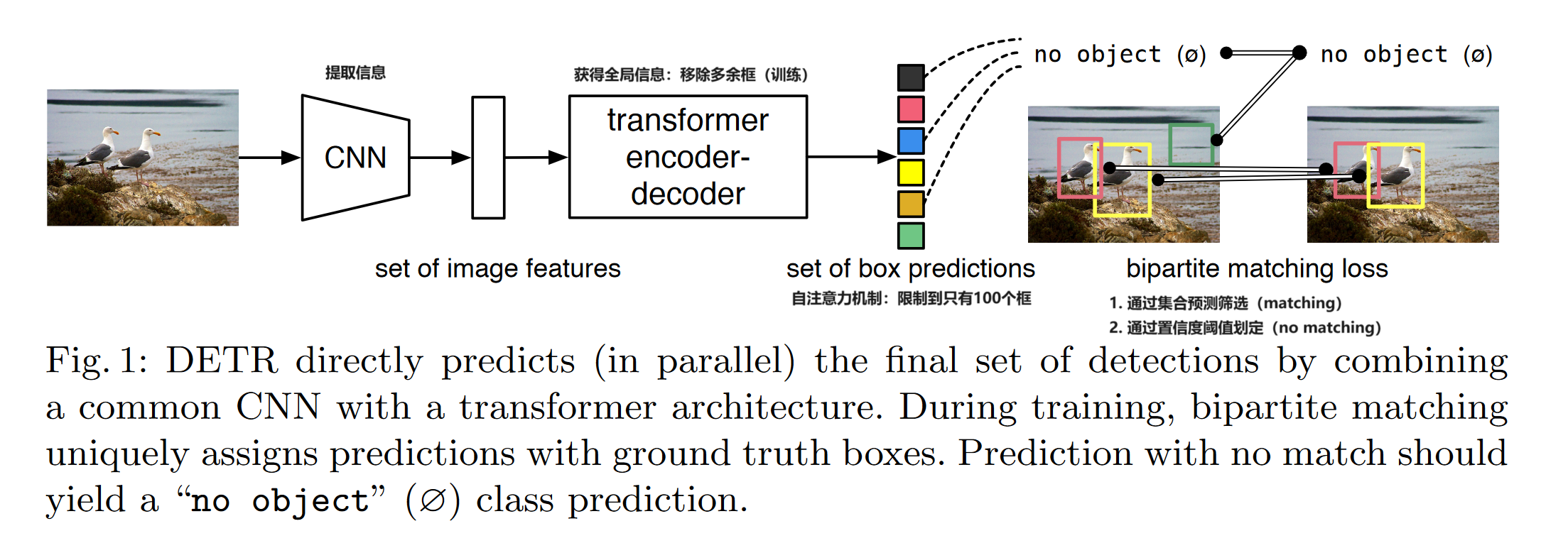
The matching part is realized through bipartite matching algorithms. The new model requires extra-long training schedule and benefits from auxiliary decoding losses in the transformer.
Object detection set prediction loss
To find a bipartite matching between these two sets we search for a permutation of
where
Then we compute the Hungarian loss, which is like:
While such approach simplify the implementation it poses an issue with relative scaling of the loss. To mitigate this issue a linear combination of the
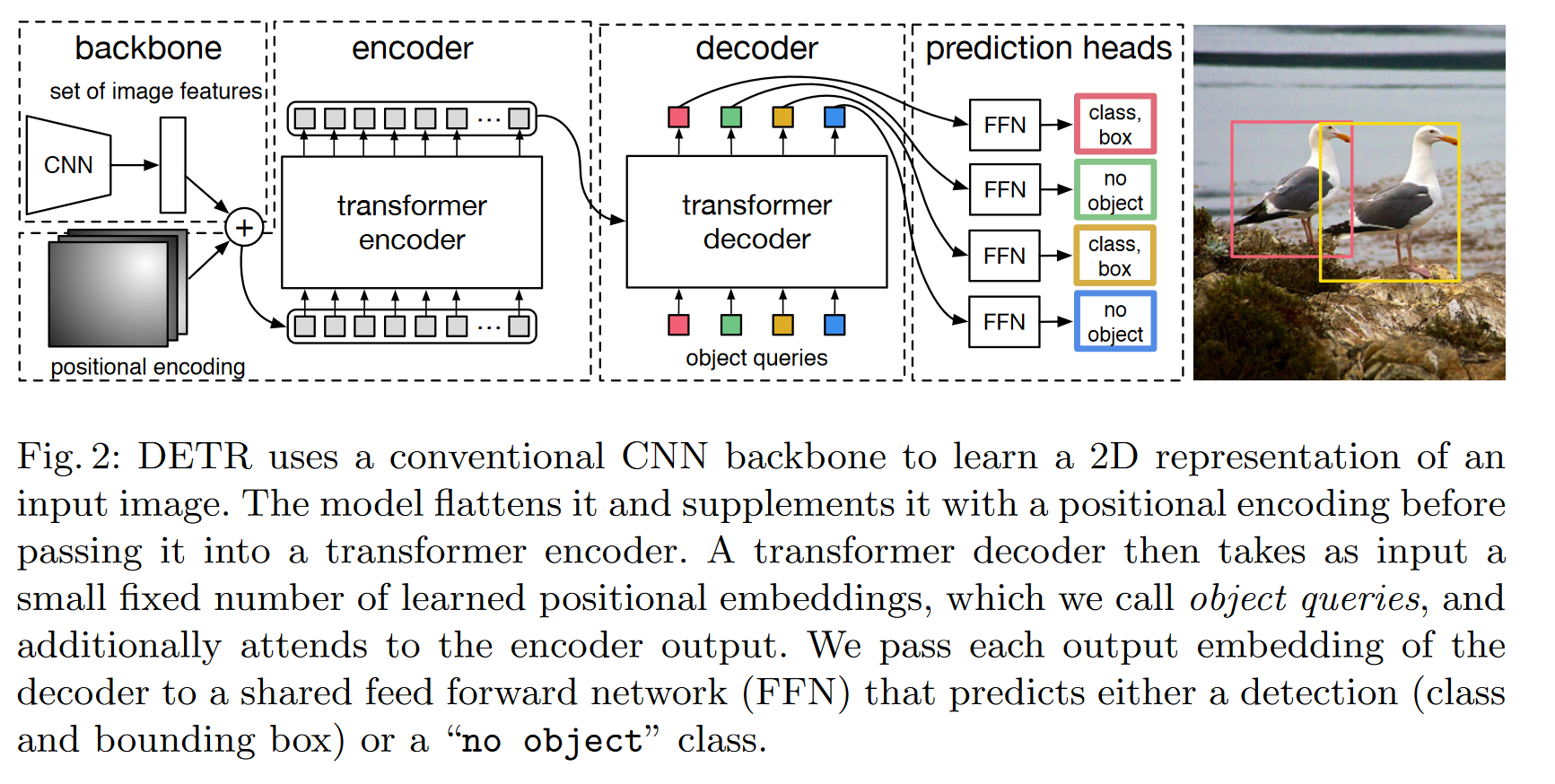
Backbone
A conventional CNN backbone with
Transformer Encoder
convolution: From dimension to . - Collapse the spatial dimensions of
into one dimension, resulting in a feature map. - Each encoder layer has a standard architecture and consists of a multi-head self-attention module and a feed forward network (FFN).
- Supplement it with fixed positional encodings.
Transformer Decoder
The decoder follows the standard architecture of the transformer, transforming
The difference is DETR decodes the
Extensions
DETR is straightforward to implement and has a flexible architecture that is easily extensible to panoptic segmentation, with competitive results. In addition, it achieves significantly better performance on large objects than Faster R-CNN, likely thanks to the processing of global information performed by the self-attention.
Reference
- Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-End Object Detection with Transformers (arXiv:2005.12872). arXiv. http://arxiv.org/abs/2005.12872
- DETR 论文精读【论文精读】